

Curso acelerado en IA
¿Tienes 20 minutos y quieres saber cómo funciona la Inteligencia Artificial generativa? Aquí es.


Abres ChatGPT (o Claude, o Gemini, o inserta tu IA favorita aquí) y te pones a conversar con él. Le pides que escriba un correo, tal vez que te ayude con tu próxima presentación o que te dé esa receta de cau cau que Germán tanto menciona y que te mueres por probar.
Pero… alguna vez te has preguntado:
¿Cómo hacen estos asistentes de IA para poder conversar con nosotros?
Si tu respuesta es algo como “porque es inteligente”, “porque aprendió de Internet”, o “porque tiene toda la información del mundo guardada”… pues no es tanto así.
ChatGPT no “entiende” realmente qué es el cau cau, no sabe que es el plato más rico del mundo (IMHO), no sabe lo que “es” el mondongo, o el ají amarillo. La verdad es que no “sabe” nada; no está pensando cuando te responde y tampoco tiene información guardada en ninguna base de datos.
Pero aun así nos responde, así que hoy quiero abrir la caja negra y tratar de explicarte todo lo que pasa cuando hablamos con la IA.
¿Empezamos?
¿De qué hablamos cuando hablamos de IA?
El mundo de la inteligencia artificial es gigante, incluye desde autos que se manejan solos hasta Netflix recomendándote tu siguiente serie. Dentro de este universo hay algo llamado IA generativa, que no es otra cosa que una IA que genera contenido nuevo (texto, imágenes, audio o video), pues te cuento que tu asistente favorito cae en esta categoría.
Para entender cómo funciona una IA, lo más fácil es empezar viendo cómo genera texto. Para eso usa algo llamado LLM.
¿Qué %&$#! son los LLMs?
¡Buena pregunta! un LLM es un Large Language Model o en español “Modelo de lenguaje grande”, piensa en él como una máquina que recibe un texto y predice cuál debería ser la siguiente palabra.
Eso es todo lo que sabe hacer, predecir la siguiente palabra en un texto, nada más. Y hace esto una y otra y otra vez:
Recibe un texto → predice la próxima palabra → Le suma esa palabra al texto
(y vuelve a empezar)
Es un modelo porque es una representación matemática, que nos permite hacer predicciones. Como los modelos del tiempo que nos dicen si va a llover o saldrá sol y podremos ir a la playa.
Sólo que este modelo no predice el tiempo sino que predice el lenguaje, y decimos que es grande porque tiene muchísimos parámetros, miles de millones de parámetros que son parte de su estructura matemática. No tienes que saber cómo funciona, solo que los usa para predecir la siguiente palabra.
Todo esto funciona en algo llamado una red neuronal.
¿Una red neuro qué?
Neuronal. Como las neuronas del cerebro, pero no tan chéveres. Son una versión matemática e hiper simplificada de la conexión entre neuronas y se usa para reconocer patrones (en nuestro caso, los patrones del lenguaje).
Imagina una red gigante con varias capas de neuronas, todas las neuronas de una capa están conectadas a cada una de las neuronas de la capa anterior y la siguiente. Esta conexión entre neuronas puede ser más o menos fuerte, a la fuerza de esa conexión entre neuronas le llamamos parámetro (también se le dice peso).
La información (el texto convertido en números, digámosle vector) viaja por esa red desde la primera capa hasta la última y dependiendo de la información que entra a una capa y de los parámetros de esa capa el vector cambia. Y así capa por capa, la información va ajustándose hasta llegar a la última capa que nos da la próxima palabra en el texto.
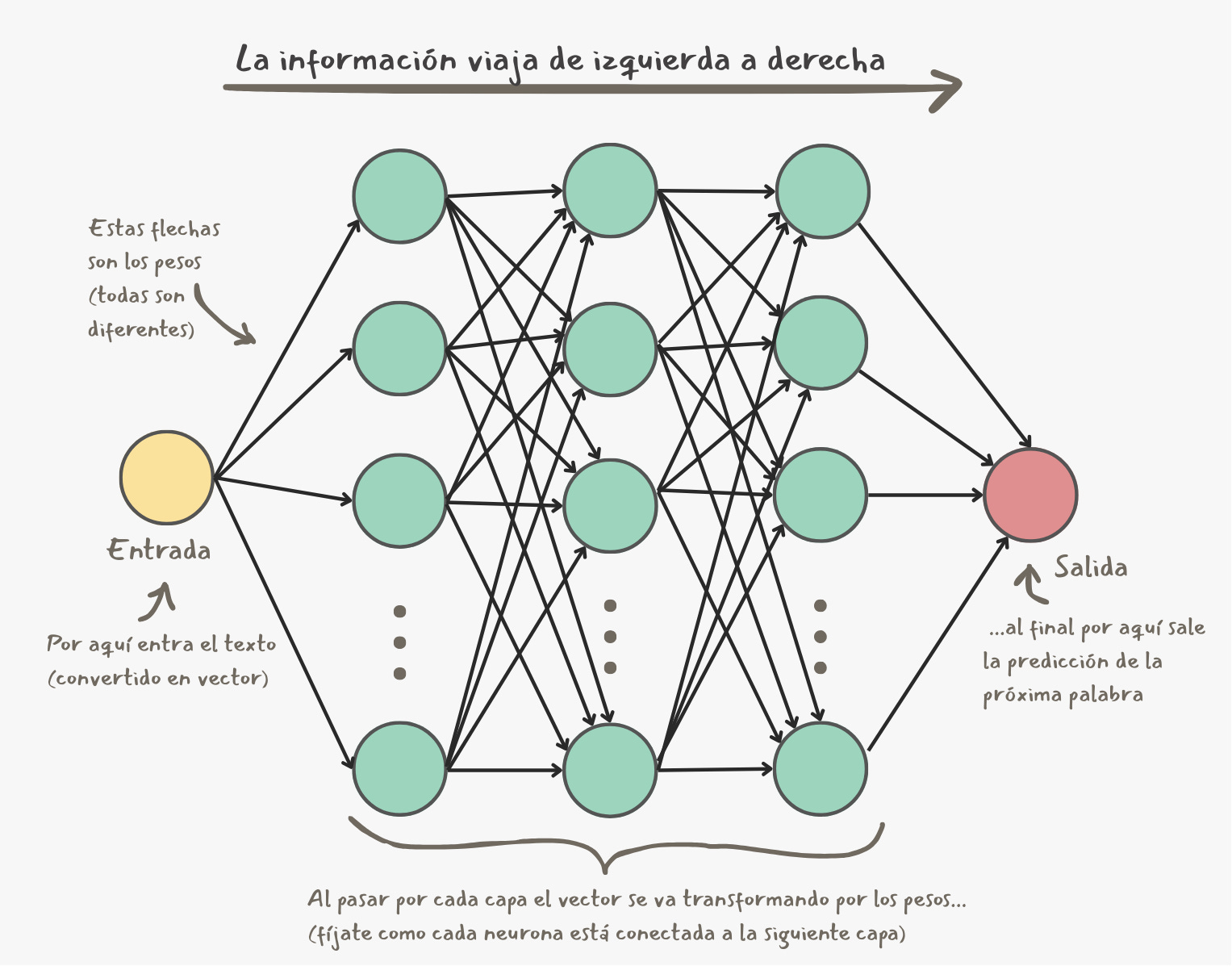
Piensa en lo grande que tiene que ser una red neuronal para llegar a tener miles de millones de parámetros. En general, mientras más parámetros tenga una red neuronal, es más capaz de entender los patrones complejos y sutilezas del lenguaje humano.
¿Y cómo hacen estas cosas para aprender nuestro lenguaje?
Entonces, ya sabemos que un LLM no es otra cosa que una máquina para predecir palabras (algo así como el teclado predictivo de tu celular, pero en esteroides). Ademas vimos que para hacerlo, usan redes neuronales con millones de parámetros.
Pero la verdad es que aún no hablamos sobre cómo hacen estas máquinas para aprender nuestro lenguaje. Y nos toca empezar preguntándonos…
¿Qué significa “aprender” para una máquina?
Pues no tiene nada que ver con cómo aprendemos los humanos. Para una máquina “aprender” significa ir ajustando sus parámetros (los pesos que conectan las neuronas en la imagen de arriba) una y otra vez hasta que la máquina se vuelve mejor haciendo su trabajo. En este caso, prediciendo la próxima palabra de un texto.
Ahora si estás listo para saberlo… estas máquinas entrenan.
Y aquí las máquinas sí entrenan como entrenamos los humanos, repiten una y otra vez su tarea y van ajustando poco a poco hasta que se vuelven muy buenas en su tarea. Eso es todo, entrenan. Como Rocky en cualquiera de sus películas (excepto en Rocky V, puaj!).
La diferencia es que en vez de salir a correr, subir escaleras, hacer sparring, cargar peso y golpear reses congeladas (¿?), las máquinas usan datos de entrenamiento.
Estos datos de entrenamiento son una cantidad obscena de texto, estamos hablando de trillones de palabras. En la data de entrenamiento de un LLM puedes encontrar miles de millones de páginas web, libros, revistas, artículos científicos, letras de canciones de reggaetón, conversaciones random de Reddit o Twitter, código de programación, Wikipedia en todos sus idiomas, etc, etc.
Y aquí viene el dato que vuelve loco a todo el que lo escucha por primera vez:
El modelo no guarda nada de esto, no tiene memoria.
No tiene una base de datos interna.
No puede buscar información ni está “recordando” lo que leyó.
Boom! No te lo esperabas, ¿cierto?
Lo que el modelo está haciendo es extraer los patrones de cómo escribimos los humanos basándose en todo lo que encuentra en los millones de textos de su data de entrenamiento.
y lo hace de la siguiente manera…
El proceso de entrenamiento
Es básicamente jugar “completa la frase” con el modelo unos cuantos trillones de veces. Para ponerlo en sencillo, el entrenamiento es algo así:
Le das un texto para completar: “Tenía hambre, así que preparé un _____”
El modelo hace su predicción: se basa en sus parámetros (esos pesos entre neuronas que vimos hace un rato), y te dice qué palabra es la que cree que sigue. Por ejemplo: “calzoncillo”
Mides el error: usando algo de matemáticas complejas comparas lo que predijo tu modelo con la respuesta correcta y ves qué tan equivocado está (en nuestro caso anda volando :P).
Ajustas los parámetros: ahí le metes más matemáticas complejas y ajustas un poquito los millones de parámetros del modelo (back propagation, le dicen) para que la próxima vez diga algo más cercano a una respuesta coherente.
Repites, repites, y vuelves a repetir (millones de veces): lo mismo pero con diferentes ejemplos.
Con cada pasada de este proceso de entrenamiento, poco a poco el modelo mejora. Al comienzo sus predicciones eran cualquier cosa (de hecho empieza con predicciones aleatorias). Luego de varias semanas y millones de pasadas, puede completar frases, responder preguntas, hacer canciones de rap y hasta escribir código de programación.

Recuerda: no es que el LLM te entienda (al menos en el sentido humano), es que conoce los patrones del idioma y puede completar frases.
Los humanos también participamos en el entrenamiento
Hay dos momentos (al menos) en donde nos metemos en este proceso.
El primero es antes del entrenamiento, cuando tenemos esos millones y millones de textos que procesar. No se trata simplemente de “descargar” todo de internet y dárselo al modelo para que entrene. No, no, no.
Las compañías como OpenAI, Anthropic, Meta, X, o Google, que se encargan de entrenar estos modelos, tienen antes que hacer una limpieza de estos textos. Filtrarlos para quitar contenido basura, direcciones de correo, datos personales, contenido sexual, violencia, etc. Y cada compañía tiene sus propias políticas de filtrado.
El segundo momento es luego del entrenamiento, con algo llamado RLHF (Reinforcement Learning from Human Feedback). Básicamente se trata de humanos evaluando las respuestas que da un modelo, y luego el modelo se ajusta según ese feedback, la idea es que con esta técnica, las respuestas del LLM se vuelven más útiles y seguras.
Fine-tuning
OK, luego de algunas semanas y varios cientos de millones de dólares ya tienes un modelo entrenado. Ahora necesitas una forma de mejorarlo sin volver a entrenarlo desde cero (a menos que quieras volver a gastar otros cientos de millones).
El fine-tuning es cuando tomas un modelo que ya está entrenado y lo entrenas un poquito más, con ejemplos específicos.
Por ejemplo, imagina que tienes tu modelo y le haces un fine-tuning con algunos miles de ejemplos de código en Python. El resultado es un modelo que puede programar mejor en ese lenguaje.
Y así, puedes hacer fine-tuning para que tu modelo sea mejor escribiendo poesía, respondiendo correos de manera sarcástica, haciendo canciones de reggaetón, escribiendo con el estilo y voz de tu marca… el cielo es el límite.
Es como tener un cocinero con muy buena técnica, y darle un curso intensivo de cocina Peruana. Ahora ese chef ya puede hacer cau cau! 👨🍳
La fecha de corte de la data de entrenamiento
Un pequeño detalle que tienes que conocer es que, una vez entrenado el modelo, no aprende nada nuevo. La data de entrenamiento tiene una fecha de corte. Es decir que el modelo no sabe nada de lo que ha pasado en el mundo desde esa fecha en adelante.
Por ejemplo cuando le pregunté a ChatGPT:
Germán
Sin buscar en internet, dime quién es el Papa.
ChatGPT
Sin buscar en internet: según mi información hasta agosto de 2025,
el Papa es Francisco (Jorge Mario Bergoglio).Esto es importante, porque por más que nuestros asistentes puedan buscar en Internet, es imposible que verifiquen cada uno de los datos de una conversación. Así que ten siempre en cuenta este gap.
La energía no es gratis
Entrenar uno de estos modelos gasta una cantidad alucinante de electricidad, una parte para correr los procesadores que hacen estos trillones de cálculos, y otra parte para enfriarlos. Eso de tener prendidas a toda máquina estas supercomputadoras durante semanas no es barato. Lo bueno es que se hace sólo de vez en cuando.

Pero una vez que el modelo ha sido entrenado es que millones de personas lo empezamos a usar al mismo tiempo. Todos pidiéndole que prediga la próxima palabra de nuestros textos, una y otra vez, todo el día, todos los días. Y aunque predecir (se llama inferencia) es más barato que el entrenamiento, el hecho de tener que hacer inferencia para millones de usuarios lo hace más caro. Probablemente entre el 80 y 90% del gasto energético de las compañías de IA sea por inferencia.
Si quieres saber más de esto, hace unos meses escribí sobre el tema.
¿Cómo funciona un LLM?
Listo, ya tenemos nuestro modelo entrenado y listo para que lo usemos. Es hora de ver, paso a paso, lo que sucede cuando le haces una pregunta.
No son palabras, son tokens
¿Recuerdas cuando te dije que un LLM predice la siguiente palabra?
Lo siento, no fui 100% sincero. 😬 Estos modelos no predicen palabras, predicen tokens.
Para un humano es natural trabajar con palabras, pero para una máquina no. Las computadoras trabajan con números, así que necesitan una forma de partir el texto en pedazos que puedan manejar, y estos pedazos se llaman tokens. Un token puede ser una palabra, un pedazo de palabra o hasta un signo de puntuación.
Por ejemplo, la frase “Voy a prepararme un Pisco Sour” tiene 9 tokens.

La máquina transforma cada uno de esos tokens a un número, en este caso:
[124855, 261, 9348, 50627, 537, 398, 13009, 148083, 13]Y nada, ahora el LLM ya tiene números con los que trabajar :)
Dato curioso, los tokens cambian con el idioma. Es decir, hay idiomas que necesitan más tokens que otros. Por ejemplo, el castellano puede llegar a necesitar 30% más tokens que el inglés. Y dado que las aplicaciones de IA suelen cobrar por token, podríamos decir que es más caro usar la IA en español.
Encima de eso, hay un límite en la cantidad de tokens que un LLM puede procesar al mismo tiempo, este límite se llama ventana de contexto.
Nota: si quieres ver cuantos tokens hay en una frase, puedes usar esta herramienta de OpenAI.
La ventana de contexto
Todo tiene un límite (excepto el amor 😘) y en el caso de los LLMs este límite es la cantidad de texto, medido en tokens, que estos modelos pueden procesar al mismo tiempo.
Imagina que el modelo es una caja, y en esta caja tiene que haber espacio para que entre el texto de tu pregunta, el texto de los documentos que subiste y además tener espacio vacío para que entre la respuesta que tu LLM genere. Todo ese “espacio” se llama ventana de contexto.
Y no solo necesitas espacio para una pregunta y respuesta, sino para toda tu conversación. Es decir, que en esa caja debe haber espacio para todas las preguntas, documentos y respuestas que tengas en un chat.
¿Entonces qué pasa cuando nuestra conversación supera la ventana de contexto? Pues dependiendo del modelo podrían pedirte amablemente que abras otro chat, o lo más probable es que tu asistente haga un resumen de la conversación y use ese resumen para seguir conversando. El problema es que en un resumen siempre se pierden detalles.
Las ventanas de contexto de nuestros asistentes son cada vez más grandes, por lo que no deberían darnos problemas. Pero creo que igual es bueno saber que existe, sobre todo porque cada día exigimos más de esta tecnología y tenemos que entender sus límites.
¿Cómo genera un LLM una respuesta?
Para generar la respuesta, estas máquinas usan algo llamado transformers (no, lamentablemente no son los robots de los 80s). Si quieres saber cómo funcionan en detalle, aquí escribí un post al respecto (y sí, uso metáforas del los robots de los 80s).
De todas formas, de manera super simplificada, siguen este proceso:
Recibe tu prompt (convertido en tokens).
Procesa esos tokens a través de su red neuronal. (usando transformers)
Predice cuál debería ser el siguiente token
Agrega el token a la secuencia
Regresa al paso 2 y repite todo otra vez hasta que termina de responder.
Por ejemplo, si yo le preguntara algo como:
¿Cuál es el principal ingrediente del cau cau?Aquí el siguiente token sería, “Mond” así que lo agregaría a la secuencia:
¿Cuál es el principal ingrediente del cau cau?
Mondluego volvería a procesar todo, mi pregunta y su respuesta, y con eso predice el siguiente token, que en este caso es “ongo”.
¿Cuál es el principal ingrediente del cau cau?
MondongoEntonces lo agrega a la secuencia, y listo.
Por cierto, la palabra “mondongo” tiene dos tokens, igual que la palabra “delicioso”. ¿Coincidencia? no creo…
Tal vez las máquinas saben más de gastronomía de lo que pensamos.

Ahora que sabemos cómo se comporta nuestro asistente, déjame contarte que de aquí se desprenden un par de cosas interesantes…
El stack
OK, acabamos de ver cómo hacemos una pregunta (o para ponernos más técnicos, un prompt) y el modelo nos responde token por token.
Hasta ahí todo bien… ¿pero qué pasa cuando interactuamos con nuestro asistente luego de su respuesta?
Pues le enviamos al LLM todas las preguntas y respuestas anteriores de la conversación.
Como oíste leíste! cada vez que le mandas un prompt, no solo está recibiendo ese prompt, sino toda la conversación. Y así es como nuestros asistentes pueden llevar el hilo cuando hablan con nosotros.
Por ejemplo, si continuáramos nuestra conversación sobre el cau cau y quisiera preguntarle “¿con qué se acompaña el cau cau?”, el mensaje que recibiría el LLM sería algo así
Usuario:
¿Cuál es el principal ingrediente del cau cau?
Asistente:
Mondongo
Usuario:
¿y con qué se acompaña el cau cau?Sí, tu LLM recibe todo eso y luego pasa por el proceso que acabamos de ver para predecir los siguientes tokens hasta que termina su respuesta.
Asistente:
Con arrozEsta lista de todos los mensajes que envías y todas las respuestas que nos da el asistente se llama “stack” o “pila” porque los mensajes de los dos roles, usuario y asistente van “apilados”.
Pero eso no es todo lo que va en el stack!
El stack tiene dos ingredientes más que son los que realmente hacen que las conversaciones con nuestros asistentes valgan la pena.
El primero se llama “system prompt” y es el primer mensaje que ve un LLM en el stack y, por lo tanto, el que guía toda la conversación. Este mensaje usualmente es hecho por las compañías que nos dan el servicio de IA para que nuestros asistentes se comporten como estas empresas quieran.
Siguiendo con nuestro ejemplo, podría ser algo así:
System prompt:
Eres un asistente experto en cocina peruana, tus respuestas deben ser cortas y al grano.Mira cómo le indicamos al LLM que función tiene y cómo debe responder.
Por supuesto, los system prompts de nuestros asistentes son mucho más complejos, pero creo que se entiende la idea.
Entonces nuestro stack ahora se ve así:
System prompt:
Eres un asistente experto en cocina peruana, tus respuestas deben ser cortas y al grano.
Usuario:
¿Cuál es el principal ingrediente del cau cau?
Asistente:
Mondongo
Usuario:
¿y con qué se acompaña el cau cau?
Asitente:
Con arrozRecuerda que todo esto va al LLM cada vez que le mandas un nuevo prompt.
El otro elemento que aparece en el stack son las instrucciones personalizadas o preferencias del usuario. Todos los asistentes tienen un lugar donde le cuentas quién eres y cómo quieres que te respondan. Esas instrucciones son una parte súper importante del stack porque son las que hacen que te responda como tú prefieres y tomando en cuenta tus preferencias.
Siguiendo con el ejemplo del cau cau, mis preferencias podrían ser algo así.
Preferencias:
Me llamo Germán, soy un fanático de la comida peruana y no me gustan las alverjitas en el arroz.Entonces el stack completo quedaría así:
System prompt:
Eres un asistente experto en cocina peruana, tus respuestas deben ser cortas y al grano.
Preferencias:
Me llamo Germán, soy un fanático de la comida peruana y no me gustan las alverjitas en el arroz.
Usuario:
¿Cuál es el principal ingrediente del cau cau?
Asistente:
Mondongo
Usuario:
¿y con qué se acompaña el cau cau?
Asitente:
Con arroz¿Te das cuenta cómo todo esto influye directamente en la respuesta?
¿Te imaginas lo que me hubiera respondido sobre el mondongo si en mis preferencias hubiese puesto que soy vegano?
Por eso es que muy importante saber cómo hacer prompts y completar las instrucciones personalizadas.
Las alucinaciones
A veces tu LLM favorito te da una respuesta que no es cierta… no creas que te está mintiendo, está alucinando (ese es el término técnico).
Las alucinaciones son algo natural de estos modelos, es una consecuencia de cómo funcionan. Recordemos por un segundo el proceso:
Recibe el stack (convertido en tokens).
Procesa esos tokens a través de su red neuronal. (usando transformers)
Predice cuál debería ser el siguiente token
Agrega el token a la secuencia
Regresa al paso 2 y repite todo otra vez hasta que termina de responder.
Ahora concentrémonos en el paso 3, la predicción del siguiente token. Lo que hace el modelo ahí, no es simplemente predecir un token, es ver qué probabilidad tiene cada token en su vocabulario de ser el siguiente. Y cuando hablamos de su vocabulario estamos hablando de un par de cientos de miles de tokens.
Entonces el paso 3 es calcular la probabilidad de todos los tokens y elegir uno de los más probables.
¿Cómo que uno de los más probables, por qué no el más probable?
Porque si siempre fuera el más probable, todas las respuestas serían muy parecidas. Si en vez de eso elegimos entre los más probables, las respuestas se vuelven más variadas y “creativas”.
Ahora que ya sabes que no siempre elige el mismo token, volamos a nuestro ejemplo del cau cau. ¿Recuerdas que el primer token que predijo fue “Mon”?
Eso quiere decir que al momento de elegir el segundo token una opción era continuar y terminar de escribir
Mondongo
Pero también hay otras opciones, algunas mucho menos probables, por ejemplo (permíteme exagerar):
Monday you can hold your head
Tuesday, Wednesday, stay in bed
Or Thursday watch the walls instead
It’s Friday, I’m in love
Basta una desviación en un mísero token y la respuesta puede cambiar completamente. Me hace acordar cómo Dr. Strange podía ver todos los futuros posibles, por más raros que sean.

Y nada, así es como alucina un modelo de lenguaje :)
Listo, terminamos (casi)
Gracias por darte este tiempo para leerme tratando de explicar cómo funciona la IA generativa. Creo que estos son los conceptos principales que nos dan una idea sólida de cómo funciona esta tecnología.
Ahora que entiendes esto, sabes lo importante que es la forma en que interactuamos con nuestros asistentes. No se trata de preguntar por preguntar, sino de estructurar una conversación.
Y creo que con esto tienes la base para que las conversaciones con tu inteligencia artificial favorita pasen al siguiente nivel.
Antes de irme, tengo una cosa más…
El cau cau
Si eres de fuera de Perú probablemente no lo conozcas, así que es hora de presentarte el cau cau, este plato que vengo usando como ejemplo y que además es mi favorito del mundo mundial.
Sí, tiene mondongo, y me encanta (aunque mis hijos, como casi todos los niños del mundo, lo odian).
Si alguna vez te sientes aventurero y encuentras un restaurante peruano que lo sirva, pruébalo. Luego me cuentas si eres team cau cau.

De nuevo gracias por leerme, espero que te haya gustado este curso acelerado en IA Generativa.
Nos vemos!
G
Muy bien explicado, llanamente y con simplicidad y buen humor este tema de la GEN IA
Hola, le pasé por curiosidad a ChatGpt, los números que se traducen en "Voy a prepararme un Pisco Sour." y me contestó que esos códigos no eran , por lo menos, de lo que "ella" estaba entrenada, que serían de alguien creativo, que no conocía esos códigos para traducirlos en palabras de ninguna IA. (¿?)