

¿Cómo hace una IA para entender un texto?
Usa algo llamado Transformer. Hoy quiero hacer un deep dive y contarte cómo funciona eso


¿Cómo hace la IA para entender un texto? La respuesta a esta pregunta tiene que ver con algo llamado atención.
Este es un tema que he venido investigado y me ha encantado, además puedes aprovechar y usarlo como tema de conversación en tu cena navideña ;)
Cuando digo atención, no estoy hablando de prestar atención (como en el cole) sino de algo un poquitito más técnico. Se trata de cómo la IA entiende la relación que tienen todas las palabras en un texto.
Para nosotros los humanos es muy fácil entender un texto. Por ejemplo si lees:
“Autobots, transfórmense y avancen”
Te das cuenta automáticamente que alguien le está dando una orden a los Autobots y que esa orden es que se primero se transformen y que luego avancen. (Me imagino que también escuchaste la voz de Optimus Prime diciéndolo).
Esto que es tan fácil para nuestro cerebro es algo extremadamente complejo para un computadora. Ellas no entienden el lenguaje como nosotros, ellas ven números y necesitan usar números para entender el texto (no te preocupes, este post no es una clase de matemáticas).
Y bueno, el mecanismo que usan ChatGPT, Claude, y todas las demás IA modernas para prestar atención se llama Transformer. De hecho, el mismo nombre GPT significa Generative Pre-trained Transformer (sí, leíste bien… transformer).

Pero para contarte por qué los transformers son probablemente la tecnología más revolucionaria para la IA, primero tenemos que ver cómo funcionaba antes…
Cómo la IA prestaba atención antes
En la antigüedad (antes del 2017), la forma en que la IA “leía un texto” era palabra por palabra.
Imagina que estás leyendo tu libro favorito, pero sólo puedes ver una palabra a la vez. Pues era algo así, para entender un texto la IA primero veía una palabra, la relacionaba con las palabras que ya había leído y luego pasaba a la siguiente palabra. Después repetía el mismo proceso.
Por ejemplo, para nuestra frase: “Autobots, transfórmense y avancen”, primero hubiera leído “Autobots” y hubiera relacionado esa palabra con las anteriores (nada en este caso, por que es la primera), luego pasa a la siguiente. Para cuando llegara a la palabra “y” la relacionaría sólo con las palabras anteriores.
Como te imaginarás, leer un texto de forma lineal, palabra por palabra no es lo más eficiente del mundo. Además, mientras más largo sea el texto, la memoria de las palabras que están más atrás se va perdiendo.
Encima de eso, leer una palabra a la vez hace que sea imposible procesar el documento de forma eficiente. No importa si lo procesas en una super computadora o en un Atari de los 80s, tienes que procesar una palabra a la vez.
Y entonces, en el 2017, la gente de Google llegó para salvarnos…
Llegaron los transformers
¿Y si en vez de procesar el texto palabra por palabra hacemos que todas las palabras se comparen entre si al mismo tiempo?
Algo así:
Esto es básicamente lo que propusieron los investigadores de Google en el paper "Attention is all you need”, y a esta arquitectura, le pusieron de nombre transformer.
Este enfoque resolvía los problemas que teníamos. Con esto ya no hay un problema de memoria porque cada palabra puede prestarle atención a cualquier otra, sin importar qué tan lejos en el documento esté. Además, permite que se procesen todas las palabras en paralelo, lo que la hace extremadamente eficiente.
Y como te mencioné al inicio, prácticamente toda IA moderna está construida sobre esta idea.
¿Enganchado? Agarra un par de tazas de café y déjame explicarte cómo funciona esto paso a paso :)
¿Cómo funciona un transformer?
Veamos paso a paso esta tecnología, desde cómo es entrenada hasta cómo genera el texto. Para empezar tienes que saber que la IA usa matemáticas para entendernos, así que en este post me escucharás decir cosas como: (no te asustes) matrices, vectores o redes neuronales. Tranquilo, que esto no es una clase de matemáticas y mi idea es que entiendas los conceptos detrás, no que hagas operaciones con matrices.
Empecemos!
Paso 0: El entrenamiento (aquí empieza todo)
Lo primero que tienes que saber es que todo esto empieza cuando los modelos de lenguaje llamados Large Language Models (LLMs) son entrenados. Para entrenar un LLM necesitamos un montón de texto, y estoy hablando de millones y millones de textos.
Básicamente le dan estos millones de textos y el modelo empieza a tratar de escribir como si fuera humano, para eso trata de predecir qué palabra es la que sigue en una secuencia y así va completando oraciones, párrafos, etc. Por supuesto que no le sale bien a la primera (ni a la segunda, ni a la tercera). El modelo se equivoca, ajusta su predicción, vuelve a intentar, se vuelve a equivocar… y así hasta que sus predicciones se vuelven suficientemente buenas. Es como aprender a montar bicicleta, te caes y te caes hasta que le agarras el truco y ya no te caes más.

Lo importante aquí es que el modelo no sólo está viendo texto, está creando y afinando las herramientas matemáticas que lo ayudan en el proceso (esas matrices, vectores y redes neuronales que te mencioné). Cada vez que el modelo ajusta su predicción, lo que está haciendo es ajustar todas estas herramientas, y esto pasa millones y millones de veces.
Lo segundo que tienes que saber es que si queremos hablar con una IA necesitamos una forma de convertir texto humano en algo que una máquina pueda procesar…
Paso 1: La IA no entiende palabras, démosle números
Por más que quieran parecer humanas, las computadoras sólo entienden números, así que necesitamos una forma de transformar las palabras en números. Si quieres impresionar al tus amigos en tu próxima cena diles que este proceso se llama embedding.
Lo que hace el embedding es transformar cada palabra en una lista de números. Para seguir impresionando, en vez de lista de números lo puedes llamar vector. Cada uno de estos vectores tiene 512 números.
Por ejemplo el embedding para la frase “Autobots, transfórmense y avancen” sería algo así:
“Autobots” →
[0.0224, 0.0018, -0.0058, …]“,” →
[0.0143, -0.0024, -0.0314, …]“transfórmense” →
[-0.0104, 0.0072, -0.0011, …]“y” →
[0.0069, -0.0407, 0.0044, …]“avancen” →
[-0.0124, 0.0197, -0.0119, …]
Hay un vector por cada palabra de la frase. Los números en estos vectores tienen muchas más decimales (algo así: 0.022477803751826286.) Esto es porque la computadora necesita este nivel de precisión para que todo funcione. Yo los abrevié para evitarme el dolor de cabeza 😅.
Y así cada palabra se transforma en una lista con 512 números.
Me imagino que te estarás preguntando para qué #$%$! necesitamos 512 números en lugar de sólo uno. ¡Buena pregunta!
Pues resulta que cada número representa una característica diferente de la palabra que el modelo aprendió durante su entrenamiento. Podemos decir que cada palabra tiene 512 dimensiones. Se trata de un espacio multidimensional.
En este espacio las palabras con significado parecido están más cerca. Por ejemplo “Mamá” y “Papá” van a esta cerca de “hija”, pero lejos de “ametralladora”. Por otro lado, las palabras “Stallone” y “Schwarzenegger” también deben estar cerca (y seguramente sí estén cerca a “ametralladora”).
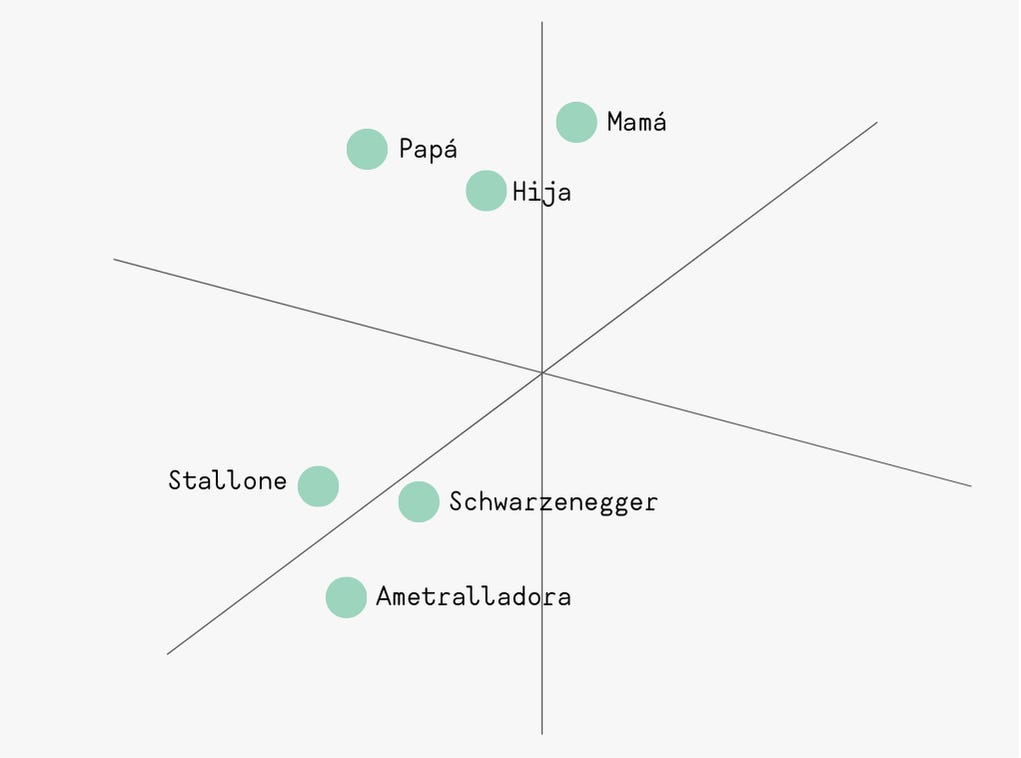
Aquí hice un ejemplo con un gráfico de 3 dimensiones (como en el colegio), la IA no usa tres, sino 512 (una dimensión por cada número en el vector). Esto de alguna forma captura que “Hija” está entre “Papá” y “Mamá”, que “Stallone” y “Schwarzenegger” están juntos; obvio, si se la pasan en películas de acción. Y “Ametralladora” muy cerca a los dos. ¿Te acuerdas cuando se peleaban para ver quien disparaba más? La idea aquí es que mientras más dimensiones usemos, más podremos entender cómo se relacionan unas palabras con otras.
OK, entonces ya tenemos una forma de darle significado a una palabra suelta y saber donde está parada con respecto a las demás, pero como el transformer procesa todas las palabras al mismo tiempo, no tiene idea del orden de esas palabras.
Es decir que no podría diferenciar estas dos frases:
“Autobots, transfórmense y avancen”
“avancen y, Autobots transfórmense”.
Para eso necesitamos una forma de decirle en qué orden están las palabras.
Y eso lo solucionamos con… otro vector de 512 números. Este vector da la posición de una palabra en el texto. Existe un vector que dice que es la posición 1, otro que es la 2, y así hasta tener tantos vectores como palabras en el texto que la IA quiere comprender.
Entonces lo que se hace es sumar cada embedding a su vector de posición y como ambos tienen 512 números podemos sumarlos elemento por elemento. De ahí queda un nuevo vector también de 512 números para cada palabra, esto se llama positional encoding. Esta nueva lista de números no sólo tiene información de cada palabra suelta, sino de en qué parte del texto se encuentra.
Con esto listo, el transformer ya puede empezar a “entender” el texto.
Paso 2: Es hora de prestar atención
Ya tenemos cada palabra convertida en un vector de 512 números que nos da idea de su significado y posición. El siguiente paso es que cada palabra “mire” como se relaciona con todas las demás. Es decir, que entienda su contexto.
Démosle otra mirada a nuestra frase:
Autobots, transfórmense y avancen
Para que una computadora pueda entender esta frase no le sirven sólo palabras sueltas, tiene que saber cómo se conectan estas palabras. Necesita que cada palabra identifique qué tan fuerte es su relación con las demás. Para ponerlo de otra manera, cada palabra se da cuenta de qué otras palabras son importantes para entenderla. Eso se llama atención.
¿Cómo hace una palabra para entender su relación con las otras palabras?
Aquí empieza lo bueno. Antes de empezar quiero contarte que esto no es tan sencillo y que por favor sigas leyendo, prometo que todo tendrá sentido más adelante.
Como te decía, para hacer esto, la IA usa sus herramientas matemáticas. En este caso, tres matrices que aprendió por sí misma durante su entrenamiento (una matriz no es más que otra lista de números). Tenemos una matriz de “llaves” (keys), una de “consultas” (queries) y una de “valores” (values).
Lo que hace es multiplicar el vector que ya tiene de cada palabra (del paso anterior) por cada una de esas 3 matrices.
Te explico:
Tenemos ya el vector de la palabra y posición. Lo primero que va a hacer la IA es multiplicarlo por la matriz de keys (llamada WK). Con eso, ese vector se va a transformar en uno nuevo que tiene más información sobre el significado de la palabra (y su posición), la idea es que esta key sea como una etiqueta, como la identidad de esa palabra. Podríamos decir que es cómo esa palabra se presenta ante las demás (como si fuera su bio de Tinder).
El siguiente paso es multiplicar el mismo vector inicial, pero ahora por la matriz de Queries (WQ). El resultado es otro vector que mide la necesidad de información que tiene esa palabra, es decir qué información necesita esa palabras de las demás. Por ejemplo “transfórmense” necesita saber QUIEN debe transformarse.
Luego, cada una de las Queries de todas las palabras se va a comparar con todas las keys de las demás palabras y se crea algo llamado una matriz de compatibilidad. Esto muestra qué tan compatibles son todas las palabras entre sí.
Para nuestra frase, sería algo como esto:

Fíjate cómo algunas palabras tienen mayor relación con otras. Por ejemplo la palabra “Autobots” está muy relacionada a “transfórmense”, pero no tanto con “y” o con la coma (“,”). Si te das cuenta, todos los números asociados a una palabra (es decir una fila de la tabla) suman 100%. Eso nos permite comparar la atención que cada palabra le da a las demás.
Aqui podemos ver la atención de la palabra avancen:
avancen: Autobots(43%) ,(2%) transfórmense(40%) y(5%) avancen(10%)Mira como todos los valores suman 100%, y como la palabra “avancen” le presta más atención a “Autobots” y “transfórmense”.
Además, una palabra también se presta atención a si misma, esto se llama auto-atención, y sirve para no “olvidarse” de su propio significado durante todo este proceso.
Pero aquí no termina la cosa. Hasta ahora sólo tenemos números de compatibilidad, es decir que sabemos qué palabras están relacionadas y qué tan fuerte es esa relación.
Ahora tenemos que saber qué información es la que cada palabra aporta. Para eso hay otra matriz (creo que eso ya te lo veías venir), te presento a la matriz de values (WV).
Igual que hicimos con Key y Query, aquí multiplicamos nuestros vectores iniciales por la matriz WV. Con esto obtenemos el vector value de cada palabra. Piensa en el value como la información que una palabra aporta.
Entonces, si key es la etiqueta que tiene una palabra, y query es lo que cada palabra está buscando, value es la información que cada palabra tiene disponible para compartir con las demás.

En resumen: las matrices WK, WQ y WV sirven para que la IA decida qué mirar, qué está buscando y qué aportan las palabras. Nada más.
Es como ir a una biblioteca y hacer una búsqueda: “Busco información sobre robots animados de los 80s” (esto sería tu query).
Cada libro tendrá una etiqueta (key) que diga cosas como “Robots”, “Dibujos animados de los 80s”, “animación”, etc.
Comparas tu búsqueda con cada una de esas etiquetas y te das cuenta que “Dibujos animados de los 80s” tiene una mayor compatibilidad.
Entonces agarras el libro y lo lees. El contenido de ese libro es el value. ¿Se entiende?
Ahora que ya tenemos el value de cada palabra, lo que hacemos es multiplicar nuestra matriz de compatibilidad por el value de cada una de las palabras.
Por ejemplo:
Nuevo vector de "avancen" =
43% del value de "Autobots"
+ 2% del value de “,”
+ 40% del value de “transfórmense”
+ 5% del value de “y”
+ 10% del value de “avancen”
Esto genera ooootro vector, que es finalmente el que tiene los datos de una palabra enriquecidos con todas las demás palabras a las que les prestó atención.
Esto. pasa. para. cada. palabra.
Paso 3: Ocho cabezas piensan mejor que una
Me pareció muy interesante eso de las matrices WK, WQ y WV, y aún más cuando me enteré que hay ocho versiones de cada una de estas matrices! 😲
Entonces, este proceso que te acabo de describir sucede al mismo tiempo con esas ocho versiones. En el mundo de la IA en vez de versiones les dicen cabezas (head, en inglés). Y usar varias cabezas para que una IA entienda cómo prestarle atención a las palabras se llama multi-head attention.
Ocho versiones
Te preguntarás algo como ¿por qué necesitamos ocho versiones de esas matrices? (yo me pregunté lo mismo). Resulta que durante el entrenamiento, cada una de esas matrices se ha especializado en mostrar diferentes tipos de relaciones entre palabras.
Cuando un humano lee una frase como “Autobots, transfórmense y avancen”, nuestro cerebro entiende inmediatamente todas las relaciones que tienen estas palabras.
En cambio, cuándo una máquina usa el mecanismo de atención que te estoy explicando, va a entender varias de estas relaciones, pero no todas. Es por eso que usamos ocho versiones. Cada versión, durante el entrenamiento, de alguna manera aprendió a detectar relaciones que las otras no. Entonces, si usamos las ocho nos aseguramos de entender en varias dimensiones estas relaciones.
Cada una de las 8 “cabezas” genera sus vectores para cada palabra, es decir que cada una tiene su propia versión enriquecida de todas las palabras.
Luego simplemente juntamos todos los ocho vectores de cada palabra en un sólo vector, y listo. Tenemos un super vector que ahora entiende a profundidad y a varios niveles el significado de una palabra y sus relaciones con todas las demás palabras.

El lenguaje humano es extremadamente complejo, más aún si quien lo quiere interpretar es un robot. Los humanos entendemos que hay diferentes capas de significado al mismo tiempo en cada frase. Cuando las máquinas usan multi-head attention pueden capturar esa complejidad.
Pero espera, que aún hay más…
Paso 4: Usemos una red neuronal :)
En este momento, cada palabra es un vector super enriquecido con información de todas las otras palabras.
Es como tener ya todos los datos de un problema escritos en una hoja. Pero aún nos falta resolver el problema. Nos toca interpretar todas esos vectores.
Para eso hay que pasarlos por una red neuronal. Imagina que una red neuronal es una caja que transforma información. Le metes los vectores y la red hace un montón de operaciones matemáticas y te devuelve otros vectores.
En nuestro caso, esta red neuronal se entreno junto con los embeddings, la matrices y todo lo que hemos visto. Es parte integral del proceso.
Entonces, cuando pasamos los vectores por esta red neuronal salen transformados, digamos que con un último toque de información. La realidad es que incluso los científicos no saben muy bien qué es lo que pasa en la red neuronal, es una especie de caja negra.

Lo que sí sabemos es que durante el entrenamiento, esta red neuronal aprendió transformaciones que hacen que sea mejor prediciendo la próxima palabra de un texto.
Después de esto, cada palabra tiene un nuevo vector :)
Este proceso se llama Feed forward, y con esto se completa una capa de transformer… pero el transformer no tiene sólo una capa…
Paso 5: Hagamos lo mismo varias veces
Todo esto que acabamos de ver, desde los embeddings iniciales, las matrices, las ocho cabezas y el feed forward es sólo una capa de la arquitectura transformer. Pues resulta que tenemos varias capas.
El vector que sale de una capa, entra de nuevo al mismo loop en la siguiente capa:
Se vuelven a usar matrices (las matrices de cada capa son diferentes).
Se vuelve a hacer el multi-head attention (las cabezas de cada capa son diferentes).
Se vuelve a pasar por el feed forward (la red neuronal de cada capa es diferente).
El vector resultante va a la siguiente capa…
Y así hasta completar todas las capas. En el paper original son seis, pero los modelos de lenguaje como como Llama (de Meta) usan ochenta. No sabemos cuantas usan modelos como ChatGPT, Gemini o Claude, pero podrían ser bastantes más.
¿Ok, pero cual es la gracia de usar varias capas?
¡Elemental, mi querido Watson! (en realidad no es elemental, pero siempre he querido usar esta frase). Veámoslo por capas partes.
¿Qué pasa con la información en cada capa?
Todas las capas hacen lo mismo. Usan la información de la atención que capta las relaciones de las palabras y la transforma con el feed forward.
Capa 1: Es la “primera pasada”. Empieza con los vectores iniciales y la atención conecta las palabras entre sí. Salen vectores con el significado de cada palabra y cómo se conectan con todas las demás palabras.
Capa 2: Tomamos los vectores que salieron de la capa 1 y los volvemos a procesar. Volviendo a nuestro ejemplo. cuando “Autobots” mira a “transfórmense” en la capa 2, ya no está mirando solo el significado de una palabra, esta mirando una versión que ya tiene información de las demás palabras (que se mezclaron en la capa 1).
Entonces, las conexiones que hace la capa 2 son más ricas en información que las que hizo la capa 1. Está empezando a conectar palabras que no estaban conectadas en la capa anterior. ¡Está empezando a entender mejor el texto! 🤯
Capas 3, 4, 5, …, ∞: Así cada capa le va agregando más entendimiento y descubriendo relaciones más complejas entre las palabras. Con cada capa adicional, nuestros vectores ganan más y más contexto, entienden más patrones en nuestro texto.
Hay una cosa más que ganamos cuando usamos varias capas. Y es que cada capa que pasa nos ayuda a conectar palabras que podrían estar un poco más alejadas.
Veamos otra vez nuestro ejemplo:
Autobots, transfórmense y avancen
En la capa 1 “Autobots” le presta atención a “transfórmense”, y obtiene la primera versión de esa palabra con sus relaciones iniciales. Pero en la capa 2, cuando “Autobots” vuelve a darle una mirada a “transfórmense”, este ultimo vector (que ha sido transformado) ahora tiene incorporada información del resto de palabras de la frase.
Entonces “Autobots” está obteniendo más contexto y puede entender mejor su relación con todos las demás palabras de la frase. En nuestro ejemplo es una frase corta, pero imagínate esto para entender un libro. Nuestro modelo puede ir afinando el entendimiento de todas las palabras del texto!
A más capas, más fino el entendimiento.

Los vectores finales que salen de la última capa y que tienen toda la información para entender el texto se llaman output embeddings. Pero nosotros podemos decirle “representación final” o si lo prefieres le ponemos “los últimos vectores” :P (cosa que suena a película de los 80s).
Paso 6: De vectores a palabras (cómo hace la IA para generar texto)
OK, entonces hemos llegado al final de este viaje. Nuestra IA ya “entendió” el texto que le dimos y nos va a “responder”. La idea de los modelos de lenguaje como ChatGPT es que siempre traten de completar la siguiente palabra y así armar sus respuestas.
Lo que hacen las IAs es tomar sólo el último vector de nuestros output embeddings. Recuerda que este output tiene un vector por cada palabra. La IA toma solo el vector que corresponde a la última palabra del texto.
¿Qué? ¿Sólo la última palabra? ¿Hemos hecho todo esto para que la IA tome sólo una palabra?
Pues sí, hemos hecho todo esto justamente para que el vector de la ultima palabra ya tenga incorporada tooooooda la información de TODAS de palabras. Recuerda que se ha enriquecido al pasar por varias capas.
Este vector pasa por una última capa (te prometo que es la última) llamada output layer o, si quieres decirlo en castellano, capa de salida.
Esta capa es otra matriz que el modelo aprendió durante su entrenamiento (te prometo que es la última). Esta matriz es gigantesca, porque su trabajo es generar un número por CADA palabra posible en su vocabulario, recuerda que los modelos modernos hablan un montón de idiomas. Ahora imagínate la cantidad de palabras que maneja (y el tamaño de esa matriz).
Entonces pasamos este vector por la matriz y nos da como resultado qué probabilidad tiene cada una de las palabras de su vocabulario de ser la siguiente palabra en la frase.
Por ejemplo, para nuestro caso:
Autobots, transfórmense y avancen
Esta capa de salida nos daría una lista de palabras y sus probabilidades, algo así:
“ahora” → 7.1%
“rápido” → 3.6%
“plátano”→ 0.0002%
“navidad” → 0.0001%
“inmediatamente” → 5.2%
“любовь” → 0.0000004%
“.” → 34.6% (fíjate como esta tiene la probabilidad más alta)
“beer” → 0.000023%
… y así las millones de palabras del vocabulario (las probabilidades suman 100%)
Al final elige la palabra con mayor probabilidad. En nuestro caso, sería “.” (con 34.6%).
Entonces nuestra IA añade esa palabra a la frase, ahora tenemos:
Autobots, transfórmense y avancen.
Fíjate en el punto al final. La IA ha hecho toooodo este proceso para “poner un punto”.
¿Y qué pasa ahora?
No me lo vas a creer…. Ahora repetimos TODO el proceso con la nueva frase (sí, esa que sólo tiene un punto más).
La nueva frase pasa por embeddings
Luego por multi-head attention y feed forward
Lo repite en todas las capas
Toma el ultimo vector
Lo pasa por el output layer
Genera probabilidades para la siguiente palabra
Agrega esa palabra a la secuencia
Y vuelve a repetir todo :)
Y así, palabra por palabra hasta terminar de responder.

¿Te has dado cuenta que cuando usas Claude o ChatGPT, ves que las palabras aparecen una por una? Pues no es efecto para que se vea más bonito, es tu IA realmente generando palabra por palabra, siguiendo este proceso una y otra vez.
Ahora entiendo por qué cuesta USD20 mensuales 😅
¿Pero la IA está de verdad “entendiendo”?
Dejemos la parte técnica por un momento y pongámonos filosóficos: ¿Estos modelos realmente están entendiendo el texto o sólo están haciendo predicciones en base a una estadística extremadamente sofisticada?
Como muchas cosas en la vida, la respuesta depende de a quién le hagas la pregunta.
Es pura estadística
Hay quienes dicen que llamar a esto “entender” es darle demasiado crédito a las máquinas. Estos modelos se entrenan con millones y millones de textos, ven los patrones estadísticos y simplemente da una predicción basándose en esos patrones.
Para este modelo “Autobot” es sólo datos, no entiende realmente de qué se trata. Nunca vio Transformers, no entiende lo que la genial serie animada significa en el mundo real.
Sí entiende (sólo depende de como definas entender)
Otras personas definen “entender” como la capacidad de capturar las relaciones semánticas, sintácticas, conceptuales y lógicas en un texto. Entonces, según esa definición, sí está entendiendo.
Todos los vectores, matrices y capas que hemos visto en este post le dan esa capacidad, estos modelos pueden explicar su “razonamiento”, adaptar su respuesta y hasta darse cuenta (a veces) que se han equivocado. ¿No es eso algún tipo de comprensión?
Es una forma diferente de “entender”
¿Por qué tenemos que comparar cómo entienden las máquinas con cómo entendemos los humanos? ¿No es posible que cada uno tenga su propia forma de “entender”?
Nosotros usamos los sentidos, razonamiento y emociones para entender algo, esa es la experiencia humana, no tiene por qué ser la experiencia de un robot. Las máquinas podrían usar patrones, estadística, redes neuronales, vectores, etc, etc para “entender”. Es simplemente otra forma.
No lo sabemos
Por último, hay quienes dicen que esta es una pregunta filosófica que no podemos responder de forma concluyente. Lo que importa es que en la práctica funciona. Tal vez la comprensión es un espectro y no un “entendió” o “no entendió”.

¿Qué opino yo?
Luego de leer, leer, y más leer para tratar de explicar este concepto, no tengo una respuesta para esto :(
Lo que sí sé es que esta tecnología permite capturar la complejidad del lenguaje humano y nos abre la puerta a interactuar con máquinas en nuestro propio idioma. Eso es algo que cuando era niño sólo veía en películas de ciencia ficción (aún no me creo que esto haya llegado antes del los autos voladores y el hoverboard de Volver al Futuro).
Creo que es una tecnología que está cambiando el mundo y vale la pena tomarse el tiempo para entenderla.
Para cerrar
Has llegado al final del post, debes haber leído unas 5000 palabras, más o menos (eso es casi como un mini ebook). Sé que fue un post técnico, denso y algo largo. Espero que toda esa charla de vectores, matrices, capas y redes neuronales haya valido la pena.
Hemos visto como funciona el transformer, una arquitectura que presentó Google en el 2017 en un paper llamado “Attention Is All You Need” y que revolucionó el mundo de la inteligencia artificial. Básicamente, si estás usando IA estás usando alguna versión de lo que vimos hoy.
Y todo esto pasa millones de veces al día, para millones de usuarios al mismo tiempo.
Con esto, ya sabes más sobre cómo funciona la IA que el 99.99% de humanos en este planeta!
Gracias por leerme, y si aun tienes energía me encantaría leer tus comentarios 🙂
Abrazo,
G
Algunas notas
Me siento Neo cuando dijo “ya sé kung-fu”, pero con transformers.
Seguro has recordado en algún momento durante este post que en el colegio pensaste “y los vectores/matrices, ¿para qué me van a servir?”
He dicho que la arquitectura transformer trabaja con palabras y eso no es del todo cierto, trabaja con tokens. Un token es la unidad mínima con la que trabajan estos modelos, y puede ser una palabra, parte de una palabra o signos de puntuación. (No te lo expliqué antes para no hacerlo más complicado).
También te dije que para predecir la siguiente palabra elige la más probable. Esto tampoco es 100% cierto, en realidad elige alguna de las más probables. Hace esto para que las respuestas sean más “creativas”.
Si siempre eligiera la palabra con la probabilidad más alta, a la misma pregunta daría exactamente la misma respuesta.Hubiera jurado que existía un transformer de varias cabezas, pero resulta que no. Mi memoria me jugó una mala pasada, suerte que tengo a Gemini para crearlo ;)
¿En qué momento deja de escribir? Se detiene cuando aparece un token especial que significa “FIN” o “ya para de escribir, cara&%$”.
De niño, mis transformers favoritos eran los Constructicons, que se convertían en Devastator.
Bumblebee siempre será un Volkswagen Escarabajo, nunca un Camaro.
Saludos a todos mis profesores con los que he visto matemáticas. Los recuerdo siempre con mucho cariño. Y sí, yo también dije “¿y cuando voy a usar esto en el mundo real?”.
Muy buena explicación sobre todo lo que hay detrás de esta tecnología que coloquialmente todo el mundo llama ChatGPT jeje. Como se podrán dar cuenta, las alucinaciones nacen de cómo genera las respuestas. Si se equivoca en una palabra, la siguiente se desviará y así sucesivamente.
Hola, Germán. Este artículo tuyo ha aparecido en la edición de hoy del Diario de Substack en español: https://columnas.substack.com/p/la-ia-va-a-sustituir-la-escritura