

¿Es más caro usar la IA en español?
Sí, el precio depende del idioma en el que le hables. En serio.


Te cuento que hace ya un tiempo vengo haciendo experimentos con n8n, una plataforma de automatización que me ha sorprendido. Básicamente es una herramienta que me permite conectar diferentes aplicaciones y crear flujos de trabajo automatizados.
Por ejemplo, armé un flujo donde un formulario pide tres cosas: un personaje, una pose y un color de fondo. Con eso, un modelo de lenguaje (Gemini) genera una descripción más detallada y luego ChatGPT produce una imagen estilo stock que termina guardada en Google Drive. Todo en automático, paso a paso, sin escribir código.
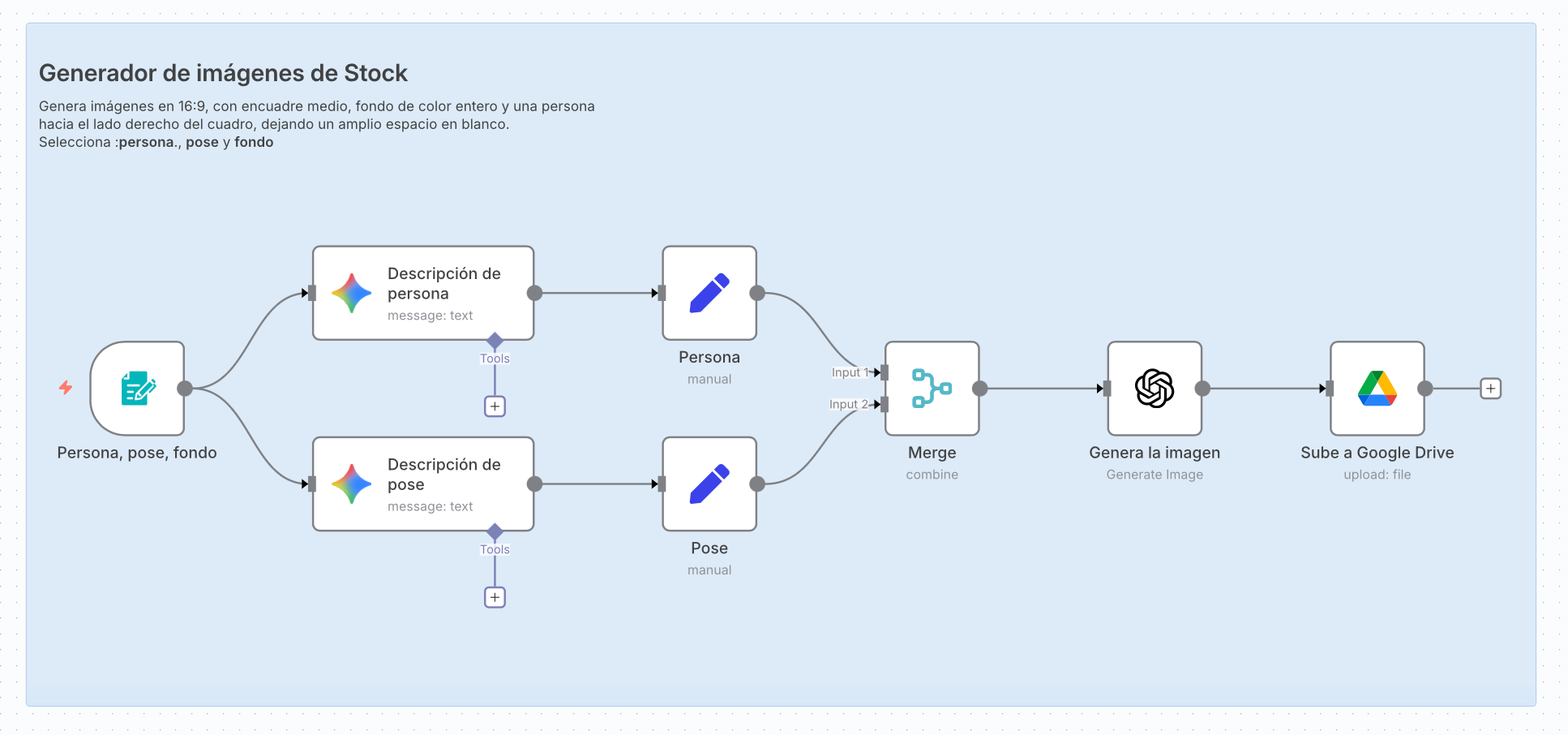
Si te dan curiosidad las imágenes que este flujo crea, aquí te dejo un par de ejemplos.


Chévere, ¿no?
No te cuento esto para presumir (bueno, tal vez sólo un poquito 😅), sino porque es una forma sencilla de ver cómo las aplicaciones se comunican con una IA.
Para generar cada una de estas imágenes no le pago a ChatGPT o a Google 20 dólares mensuales, cada imagen me cuesta centavos.
Lo realmente impactante aquí no son las imágenes (aunque admito que estoy muy orgulloso de ese flujo). Lo impactante es que Google y OpenAI me cobran más por usar español que inglés.
Este post es sobre eso.
¿Me cobran por palabra?, ¡por palabra!
Sí. Te cobran por palabra… bueno, más o menos. Te explico.
Los sistemas no “conversan” con los LLM como ChatGPT o Claude como lo hacemos los humanos. En vez de usar su web o aplicación móvil, los sistemas usan algo llamado API (application programming interface) que es una forma de comunicarse con los LLMs usando código.
Esta diferencia en cómo usas el modelo también cambia cómo te cobran. Para usar un API no se paga una mensualidad fija (no es Netflix), se paga por la información que procesas.
Cada vez que le mandas texto a la IA por medio del API te cobran. Esto tiene sentido porque el texto que le envías tiene que ser analizado y respondido; esto necesita servidores, electricidad, tiempo de procesamiento, etc. Es como la cuenta de la luz, mientras más consumes, más pagas (maldito hervidor eléctrico).
Para cobrarte, estas empresas necesitan poder “contar” cuanto texto se usa cuando interactuamos con el modelo. Para nosotros los humanos, es natural dividir el texto en palabras, pero para las máquinas es un poco diferente. En vez de palabras ellas usan algo llamado tokens.
Los tokens son algo así como la unidad mínima de texto que un LLM entiende, usualmente son partes de una palabra o hasta signos de puntuación o espacios.
Cada vez que le mandas texto a la IA, esta divide el texto en tokens, los procesa y usa tokens para generar la respuesta. Al final te cobran según la cantidad total de tokens que usaste en esa consulta (incluyendo la pregunta y la respuesta). ¿Sencillo, no?
Es como si Netflix nos cobrara por cada megabyte de streaming que usamos. Si nos enganchamos con una serie (a quién no le ha pasado) pagaríamos más que si vemos una película ocasional.
Hasta aquí todo bien, pero hay un tema con los tokens… la cantidad que usas depende del idioma.
¿Entonces hay idiomas más “caros” que otros?
Yes, sir! Hay idiomas más caros que otros.
Hagamos la prueba contando los tokens de diferentes frases. Para hacer esto voy a usar una herramienta de OpenAI llamada Tokenizer, que nos da la cantidad de tokens de un texto. Puedes probarla a mano aquí, o hacer como yo y escribir un pequeño programa en Python para contar los tokens (lo sé, a veces soy un marciano :P).
Empecé con algo súper sencillo:
Español: “Gracias” → 2 tokens
Inglés: “Thanks” → 1 token
Portugués: “Obrigado” → 3 tokens
Japonés: “ありがとう” → 1 token
Parece que ser amable en español cuesta el doble que en inglés o japonés, aunque andamos un poquito mejor que el portugués. (por cierto, todos estos experimentos los hice con el tokenizer de GPT-4).
¿Qué pasará con una oración más compleja?
Español: “Tengo sed, creo que iré por una cerveza.” → 14 tokens
Inglés: “I’m thirsty, I think I’ll go for a beer.” → 13 tokens
Bueno, es sólo un token más en español que en inglés, así que no podemos decir que es mucho más caro… pero todo va sumando y esas cervezas no son gratis ;)
Y ya que estamos, compliquemos un poco más la frase preguntando por comida:
Español:
“Haz una búsqueda en Internet sobre platos de cocina peruana y dime el top 5 para un paladar extranjero.” → 26 tokensInglés:
“Do an internet search about Peruvian dishes and tell me the top 5 for a foreign palate.” → 20 tokens
Se ve un poco más la diferencia entre los idiomas, hacer la pregunta en español cuesta 30% más. Y eso no es nada, Hay idiomas que usan muchos más tokens que el español. Por ejemplo el Árabe, Tailandés, y, con la medalla de oro, el Birmano.
Aquí el mismo ejemplo de la pregunta por los platos de comida peruana en esos idiomas:
Árabe:
“ابحث في الإنترنت عن أطباق المطبخ البيروفي وأخبرني بأفضل خمسة أطباق تناسب ذوق الأجانب.” → son 62 tokens!!!Tailandés:
“ลองค้นหาในอินเทอร์เน็ตเกี่ยวกับอาหารเปรู แล้วบอกฉัน 5 อันดับที่เหมาะกับรสนิยมของชาวต่างชาติ” → y aquí 82 tokens!!!Birmano:
“အင်တာနက်မှာ ပီရူးအစားအစာတွေကို ရှာဖွေပြီး နိုင်ငံခြားစားသမားတွေအတွက် ထိပ်တန်း ၅ မျိုးကို ပြောပေးပါ။” → record mundial con 193 tokens!!!!
¿Te das cuenta como según el idioma que hables, consultar una IA no cuesta lo mismo? Todo bien si lo haces en inglés, es un poco más caro en español y puede llegar a ser, 3, 4 y hasta casi casi 10 veces más caro en otros idiomas.
Y en mi caso no tengo que ir tan lejos. Aquí en el Perú se hablan otros idiomas ademas del castellano, como el Quechua y el Aymara.
Probemos el mismo ejemplo:
Aymara: “Internet tuqina Piruw manq’añanak thaqhata, markanakar chhijllatirinakapa amtäwi layku phisqha nayrïri sum manq’añanak qhanañcht’asma.” → 58 tokens
Quechua: “Internetpi Piruw mikhunakunata maskhay, huk watuq runapaq aswan sumaq 5 mikhunata willaway” → 33 tokens
Hay que tener en mente que estos tokens extras no sólo se aplican en la prompt, sino en la respuesta que nos da la IA. Claramente esto no ayuda a democratizar el uso de esta tecnología en el mundo :(
¿Entonces la IA está optimizada para hablarle en inglés?
En corto sí, pero no es a propósito. Es consecuencia de cómo se construyen estos sistemas.
Para explicártelo empecemos hablando de cómo se generan los tokens.
El Tokenizer
Por más que suene así, el tokenizer no es un producto que vas a encontrar en el canal de ventas por televisión junto al “Jack LaLanne Power Juicer” (¿soy el único aquí que se pasó su niñez viendo eso?).
Un tokenizer es la parte de un modelo de lenguaje que se encarga de convertir el texto en unidades más pequeñas llamadas tokens.
Básicamente revisa millones de textos y empieza a buscar patrones que se repitan. Por ejemplo, si ve las letras “e-s-c-r-i-b-i-e-n-d-o” va a buscar qué pedacitos de ese conjunto de letras se repiten con mucha frecuencia en su data de entrenamiento. Y en este caso encuentra que se repiten las combinaciones “e-s”, “c-r-i”, “b-i”, “e-n-d-o”, así que separa esa palabra en 4 tokens.

Ahora que sabemos cómo se generan estos tokens, déjame contarte las dos razones por las que la IA está “optimizada” para el inglés.
El inglés es más compacto
Este idioma suele usar en general palabras más cortas, por ejemplo ellos dicen “cat”, nosotros “gato”; nosotros decimos “comida” (¡3 sílabas!) y ellos “food”.
Encima de eso, en español tenemos tal cantidad de conjugaciones que le da dolor de cabeza a cualquier angloparlante que quiera aprender el idioma. “hablo”, “hablas”, “habla”, “hablamos”, “habláis”, “hablan”, “hablé”, “hablaste”, “hablaríamos”… tú me entiendes. En inglés, básicamente tienes “speak”, “speaks” y “spoke”. A menos variantes, menos tokens.
Los tokenizers se entrenan con datos
Ok! Si te diste cuenta, cuando te conté cómo funciona un tokenizer obvié muy elegantemente explicarte lo de su data de entrenamiento. Ahora ya no me salvo.
Puedes imaginar la data de entrenamiento como una montaña de texto que incluye, libros, artículos, noticias, páginas web, poemas, canciones de reggaetón, etc.
Nuestro amigo, el tokenizer se encarga de “leer” toda esta data una y otra vez y buscar patrones sobre qué letras aparecen juntas más seguido. Al final del proceso tiene esas combinaciones de letras que aparecen juntas serán sus tokens.
Ahora viene el plot twist… el 90% de los textos con los que se entrena el tokenizer están en inglés!! Entonces es obvio que los patrones que más encuentre sean los de ese idioma, haciéndolo el más eficiente.
Esta diferencia de idiomas también tiene un impacto en la calidad de las respuestas que nos da la IA, pero antes de pasar a eso, quiero enseñarte una hermosa coincidencia que acabo de encontrar. Mi nombre tiene la misma cantidad de tokens que el de Obi-Wan Kenobi. (debe ser una señal del universo).

¿Y encima las respuestas no son igual de buenas en otros idiomas?
Exacto! Pero no me mal entiendas, tampoco es que sean malas. Dame un minuto para explicarte las dos razones por las que no son igual de buenas que en inglés.
Mientas más tokens hay, más difícil es comprender algo
¿Te acuerdas que mi pregunta sobre comida peruana usaba 20 tokens en inglés, 26 en español y se disparaba a 58 en aymara, 82 en tailandés y hasta 193 en birmano?
Pues mientras más tokens haya que procesar, más complicado es que la IA entienda el contexto completo de lo que le estás diciendo (además de ser más caro). Piénsalo como que tu IA tiene que interpretar más piezas de información para entender la misma idea.
Realmente no es tan políglota como parece
¿Recuerdas la montaña de datos de entrenamiento y como estaba 90% compuesta de texto en inglés?
Eso significa que si bien entiende todos los idiomas, tiene muuuuuuuucha más experiencia con los patrones, contexto, y sutilezas del inglés. Además, si hablamos de conocimiento muy de nicho, lo más probable es que sus únicas fuentes sean en inglés, por lo que responderá mejor.
No es que las respuestas que nos da la IA en otros idiomas sean malas, de hecho son muy buenas. Es sólo que las respuestas en inglés son un poquito mejores. Y si le sumas el hecho que estas respuestas son más caras en otros idiomas, pues… así estamos…
Lo que pagas por IA depende de tu idioma
Sí, cuando usas estos modelos de lenguaje por medio de su API.
Claramente no si es que estás suscrito al plan mensual. De todas formas creo que es muy importante conocer esta diferencia.
Sabemos que no es una conspiración (¿lo sabemos? :P), tampoco es que quienes diseñaron estos sistemas sean malvados. Es simplemente como funciona esta tecnología y la cantidad de data que existe en el mundo.

La realidad es que si eres de los que hablamos español, francés, quechua, tailandés o algún otro idioma que no sea inglés, vamos a usar más tokens y terminar pagando más por usar nuestra IA favorita. Sin mencionar que las respuestas van a ser un cachito menos buenas que en inglés.
Las compañías de IA conocen muy bien esta limitación y están trabajando activamente en reducir esta brecha. Para esto están mejorando sus modelos de tokenización y tratando de representar mejor otros idiomas en la data de entrenamiento. Así que espero que con el tiempo esto mejore, aunque no sé si el gap se logre eliminar por completo.
Hay algunas estrategias para tratar de mejorar esto, cómo hablarle en inglés a la IA (algo que suelo hacer) o pedirle a la misma IA que traduzca antes de responder.
Ninguna de estas soluciones es perfecta. Y aunque te repito que las respuestas en tu idioma son muy buenas, es importante conocer las limitaciones que tenemos cuando usamos esta tecnología.
Y eso es, espero que te haya gustado el post :)
Sólo tengo una cosa más que decir…
One more thing (off topic)
Me he pasado viendo las recomendaciones en diferentes idiomas de ChatGPT sobre los 5 platos peruanos. Son buenas, pero ya que estamos, quería dejarte los 5 que creo que deberías probar :P.
Así que busca el restaurant peruano de tu barrio y dile a chef que Germán te ha recomendado probar:
Ceviche: no puede faltar, prueba el de pescado y el de pulpo. (va perfecto con una cerveza bien helada).
Cau-cau: lo sé, es mondongo (y no es para todos) pero es mi plato favorito y no podía faltar. Hay diferentes recetas. Si te atreves a pedirlo, que no le pongan ni alverjas ni zanahoria. Se come con arroz.
Seco de cabrito: es una maravilla, tienen que servírtelo con frejoles, arroz, tamalito verde y zarza criolla. (si no, no vale).
Papa rellena: no te imaginas lo que es. Aprovecha para pedir algunas salsas peruanas para acompañar como la Huancaína o la Ocopa.
Anticuchos: Nuestra street food por excelencia. Sí, es corazón de vaca a la parrilla macerado con un menjunje de ají panca y especias.
Listo, ahora sí puedo irme tranquilo.
Cuéntame qué te pareció el post. Tienes puntos extra si pruebas estos platos (medalla al valor si pruebas el cau-cau).
Abrazo,
G
Excelente, buen post para mi tokenizado cerebro...eres un maestro Germán!
Buena aclaración general.
Podrías aprovechar tus experiencias en n8n y darnos unos cursos del tema, seguro que hay más gente como yo que lo agradecería.
Saludos